
[TOC]
0. 들어가며
내가 이 쪽 분야로 오게된 계기였던 Generative Model에 대해서 다시금 공부해보고자 한다. 우선은 최근 유행하는 부분들을 보기 전에 전통적인 방식들부터 다시 한번 복습해보고자 한다.
1. Discriminative Model의 간단한 요약 정리
1.1 Linear Regression
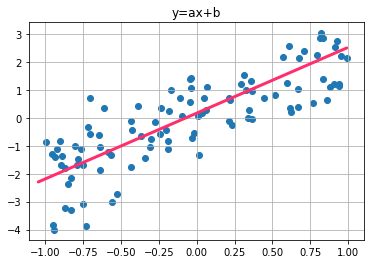
선형회귀란 우리가 가진 데이터가 어떤 함수로부터 생성되었는가를 알아보는 함수관계를 추측하는데에서 출발한다. 종속 변수 y와 한개 이상의 독립변수 x와의 선형 상관관계를 모델링하는 회귀분석 기법이다. 즉 기존 데이터를 기반으로 생성된 모델로 새로운 데이터를 이 모델에 넣었을때 어떤 값이 될지 예측하는 문제이다. 다만 Linear Regression은 설명변수가 연속형일때만 사용 가능하고 범주형 변수일 경우 이를 Dummy Variable로 변환하여 회귀분석을 적용해야 한다. 여기서는 단순히 \(y=ax+b\)(Input이 되는 설명변수가 x의 1개)의 단순 선형회귀분석을 예로 든다.
-
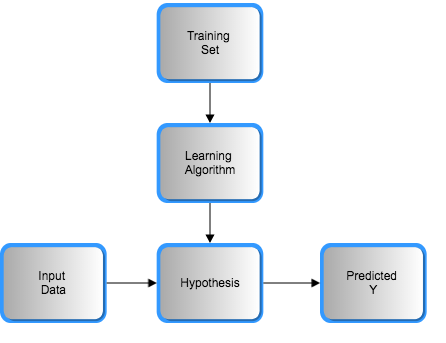
회귀분석1의 개념적 순서는 우리가 이미 가진 Data(Training set)을 가지고 Learning Algorithm으로 우리의 가설(Hypothesis: h, 혹은 Model)을 만든다. 이 모델(일반적으론 \(y = ax + b\)이라는 하나의 직선)을 기반으로 새로운 데이터 x를 예측된 결과 y로 만든다.
-
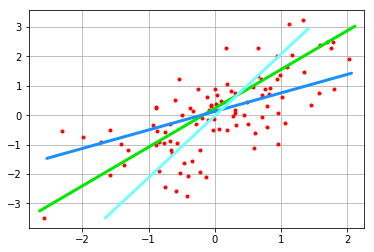
우리가 만들고자 하는 모델은 우리가 가진 training Set과 가장 차이가 작은, 즉 Training set을 Scatter plot등으로 그렸을때 모든 점과 가장 가까이 지나가는 선을 긋는 것이다.
-
그러면 우리가 만들고자 하는 하나의 직선은 어떻게 그어야 할까? 하나의 Training Set에서도 위 그림과 같이 다양하게 직선을 그을수 있다. 위에서도 언급하였지만 우리는 우리가 그은 선과 찍은 저 모든 빨간점들과의 거리가 가장 작은 선을 긋는다. 여기서 점들과 선의 거리(오차)를 구하는 식을
Cost Function이라 한다.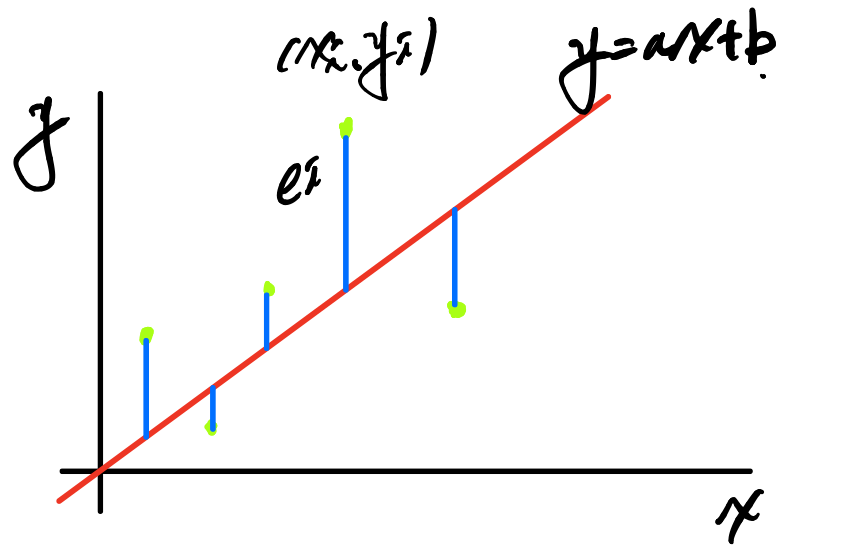 우리가 가진 데이터 Training set(초록점)과 우리가 예측한 모델(빨간선)과의 거리 즉 오차(파란선)을 그림으로 그려보면 위와 같다.
우리가 가진 데이터 Training set(초록점)과 우리가 예측한 모델(빨간선)과의 거리 즉 오차(파란선)을 그림으로 그려보면 위와 같다. -
일반적으로 Linear Regression에서는 저 오차를 구하기 위해서 우리는 위에서 언급한 Cost Function(비용함수)2라는 것으로 우리가 만든 모델이 얼마나 일을 잘했나 못했나를 판단 내린다. 여기서 우리는 Cost function으로 소위 말하는 Squared Error Function을 사용한다3. 이 Cost function의 식은 아래와 같다.
\[\begin{aligned} Cost(\theta)= \frac{1}{2}\sum_{i=1}^{m} =\left(h_\theta \left(x^{\left(i \right)}\right)-y^{\left(i\right)}\right)^2 \end{aligned}\]소위 통계에서 말하는 편차제곱합의 식이랑 같다. 편차제곱합은 결국엔 편차의 제곱들의 합이고, 원래의 값에서 평균(우리의 경우는 평균은 진짜 값)을 뺀 값 제곱의 합, 편차를 제곱한 값들의 합의 식이다. 이것은 결국엔 표본 내 개인차(변산성)의 총량을 의미한다. 추가로 보통 많이들 사용하는 평균제곱오차(Mean Squared Error: MSE)의 식은 위의 식에서 변수의 갯수 m으로 나눠준 식이다(평균으로 만들어준다!).
\[\begin{aligned} Cost(\theta)= \frac{1}{2}\frac{1}{m}\sum_{i=1}^{m} =\left(h_\theta \left(x^{\left(i \right)}\right)-y^{\left(i\right)}\right)^2 \\ \end{aligned}\]이 식은 사실 통계에서의 분산…을 구하는 식이랑 같지않나 싶다(아니 식이 같은데!). 결국엔 우리가 만든 Model의 분산을 구한다는 느낌으로 접근을 하는것같다4.
아마도 회귀분석에서 말하는 MSE는 표본분포에서 표본분산을 뜻하는 것 같다.
쨋든간에 MSE는 오차항의 분산(\(\sigma^2\))의 불편추정량5이다. 그리고 이 오차항은 정규 분포를 따른다고 전제한다. 우리는 우리가 가진 Training Set 즉 전체에 존재하는 데이터(모집단)의 Sample Data를 가지고 있다고 전제를 하고 이 Sample Data로 모집단을 추측하는 것이다.- 추가로 식에서 \(\frac{1}{2}\)이 붙는 이유는 우리는 얼마나 변하는지에 대한 값을 구하는 거라서 2를 곱하건 2를 나누건 상관이 없다(수학적으로 멋있는 표현이 생각나질 않는다). 하지만 저 \(\frac{1}{2}\)를 취하므로 후에 경사하강법(Gradient Descent)으로 최적의 값을 구할때 미분을 하기 편하게(제곱값의 2가 사라지도록)하는 향신료이다.
-
이 Linear Regression의 확률적 해석은 아래와 같다.
-
우리는 우리의 예측값 y와 input값 x, 그리고 오차인 \(\epsilon\)으로 식을 가정한다.
\[\begin{aligned} y^i =&\ \theta^{T}x^{i} + \epsilon^{i} \\ \epsilon^{i} =&\ y^{i} - \theta^{T}x^{i} \end{aligned}\]즉 원래 값인 \(y\)에 오차 \(\epsilon^i\)를 합치면 예측값인 \(y^i\)가 나온다6.
-
그리고 위에서 말 한것처럼 오차항은 정규 분포를 따른다고 가정을 해보면 \(\epsilon \sim \mathcal{N}\left(0, 1\right)\) 이다7.
-
위의 1,2 두 가정을 결합하면 조건부 확률 \(P\left(Y\vert X:\theta\right)\)를 정의하는 것이 가능하다.
\[\begin{aligned} P\left[y^{\left(i\right)}\vert x^{\left(i\right)}:\theta\right] =& \ \frac{1}{\sigma\sqrt{2\pi}}exp\left(-\frac{\left(y^{\left(i\right)}-\theta^{T}x^{\left(i\right)}\right)^{2}}{2\sigma^{2}}\right) \\ P\left[y^{\left(i\right)}\vert x^{\left(i\right)}:\theta\right] \sim& \ \mathcal{N}\left(\theta^{T}x^{\left(i\right)}, \sigma^{2}\right) \end{aligned}\]로 유도가 가능하다.
-
\(\theta\)에 대한 Likelihood8함수
\[\begin{aligned} L\left(\theta\right) = &\ \prod_{i=1}^{m}P\left[y^{\left(i\right)}\vert x^{\left(i\right)}:\theta\right] \\ =&\ \prod_{i=1}^{m}\frac{1}{\theta\sqrt{2\pi}}\exp\left(-\frac{\left(y^{\left(i\right)}-\theta^{T}x^{\left(i\right)}\right)^{2}}{2\pi^{2}}\right) \end{aligned}\] -
최대우도추정(Maximum Likelihood Estimation: MLE)는 Likelihood를 최대화하는 \(\theta\)를 추정하는 방법이다. 보통은 log-likelihood를 최대화한다.
\[\begin{aligned} \mathcal{l}\left(\theta\right) =&\ \log L\left(\theta\right) \\ =&\ \log\prod_{i=1}^{m}\frac{1}{\sigma\sqrt{2\pi}}\exp\left(-\frac{\left(y^{\left(i\right)}-\theta^{T}x^{\left(i\right)}\right)^{2}}{2\sigma^{2}}\right) \\ =&\ m\log\frac{1}{\sigma\sqrt{2\pi}}-\frac{1}{\sigma^{2}}\frac{1}{2}\sum_{i=1}^{m}\left(y^{\left(i\right)}-\theta^{T}x^{\left(i\right)}\right)^2 \\ \implies&\ \frac{1}{2}\sum_{i=1}^{m}\left(y^{\left(i\right)}-\theta^{T}x^{\left(i\right)}\right)^{2} \end{aligned}\]라는 식이 나오며 이 결과는 위에서 우리가 가정했던 Cost Function인 Squared Error Fucnction이랑 같다.(위의 식에서 미분하는 부분은 생략하고 결과만 표시되었다..) MLE에 대해서는 링크를 확인하자.
-
-
결국엔 Linear Regression의 확률적 해석을 정리하면
- 변수 X, Y들의 관계를 확률적 모형 \(P(Y\vert X)\)로 가정하고, Likelihood를 함수정의 하였다.
- MLE를 통해서 최적의 해 \(\theta\)를 찾았는데, 이 해를 찾는 과정은 편차제곱(Least Square )을 Minimize하는 것과 같다는 증명을 하였다.
- 확률 분포를 활용한 모델링은 Linear Regression에서 Cost function으로 편차제곱의 합를 최소화 하는 Least-Square cost를 사용하는 것에 대한 확률적 가정에 논리적 근거를 제시한다.
-
우리가 만든 심플한 모델은 어떠한 값(x)이 input되었을 때 y라는 예측값을 찾는 것이다. 인간들이야 느낌(?)내지는 경험으로 이게 어느정도 원본이랑 일치한다!라는 것을 판단할 수 있지만 컴퓨터한테는 생각(…)이 없다. 그래서 컴퓨터가 어떤식으로 우리가 예측한(우리의 가설 Hypothesis)랑 원본이랑 비교할지를 알려주어야 한다(간단하게는 틀렸는지 맞았는지의 여부와 복잡하게는 얼마나 틀렸는까지). 이 판단하는 방법으로 Cost Function이라는 것을 정의해준다. 그리고 우리는 Linear Regression에서의 Cost Function, 즉 컴퓨터가 판단하는 원본과 얼마나 다른지를 판단하는 방법으로 Squared Error Function(Least-Square cost, 편차제곱합)이라는 것을 활용하였다. 이는 우리가 세운 가설 H라는 하나의 선을 기준으로 input된 값인 x들과의 물리적 거리를 최소화하는 방식이다. ….라는 정도로 요약할 수 있지 않을까 싶다.
-
pytorch와 함께하는 Linear Regression의 구현!
import torch import numpy as np from torch.autograd import Variable # Autograd from torch import nn # Basic Neural Network Module import matplotlib.pyplot as plt # Needs for Ploting # Data 정의 sample_size = 100 x = torch.FloatTensor(sample_size, 1).uniform_(-1, 1) y = 2*x + torch.randn(x.size()) plt.scatter(x, y) plt.title("y=ax+b") plt.grid() plt.show() # Model 정의 model = nn.Linear(1, 1, bias=True) cost_function = nn.MSELoss() # Mean Squared Cost Function optimizer = torch.optim.SGD(model.parameters(), lr=0.05) # 일단 그려려니 하고 넘어가자 print(model) print(model.weight, model.bias) # Training epoch = 100 for step in range(epoch): prediction = model(x) # model에 x를 넣어서 예측값을 만든다. cost = cost_function(prediction, y) # cost function으로 얼마나 잘했는지 판단(예측, 원결과) optimizer.zero_grad() # 일단은 그려려니하고 넘어가자 cost.backward() optimizer.step() if not(step % 20): plt.cla() plt.scatter(x, y) plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=1) plt.title('cost=%.4f, w=%.4f, b=%.4f' % (cost.item(), model.weight.item(),model.bias.item()), fontdict={'size': 20} ) plt.grid() plt.show() plt.pause(0.1)위 코드는 간단히 python과 pytorch로 구현하였다.
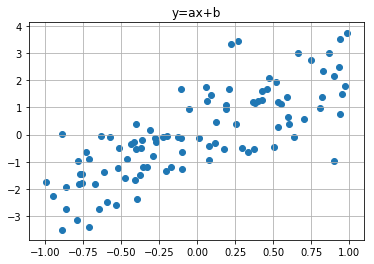
우선 데이터는 위의 표와 같이 준비되어 있으며 우리는 저 데이터를 가장 잘 구분하는 선을 찾는다.
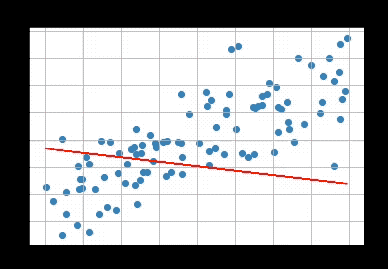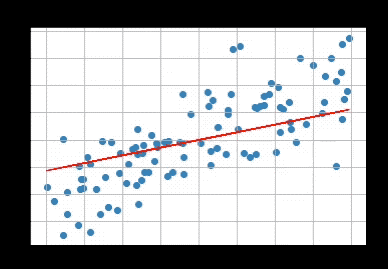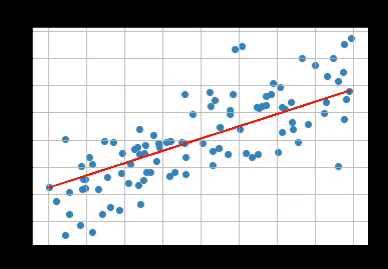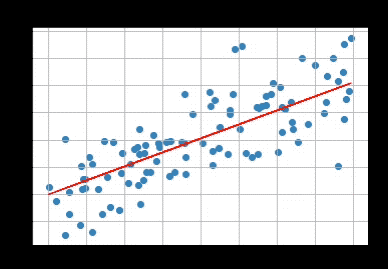
맨 처음에 우하단으로 향하는 선이었다가 점점 최적화가 되는 모습을 볼 수 있다.
위 실행코드는 여기에서 볼 수 있다.
-
회귀분석이라는 이름은 X값에 따른 모든 Y값들이 평군으로 회귀한다라는 뜻이라고 한다. ↩
-
여기서 사용되는 Cost Function, 즉 Error를 어떤 함수를 사용하는 것에 대한 가정 역시 모델링의 일부분이다. ↩
-
Mean Squred Error가 아니다!(지금은…) ↩
-
(그렇다고 치면 MSE를 구할떄는 사실 자유도를 상정해서 계산을 해야하는거 아닌가.. 싶긴하지만 일단은 넘어가보자) ↩
-
우리가 추측한 기대값이 추정할 모수의 실제값과 일치하는 추정치. 즉 우리가 뽑은 샘플이 전체랑 같다고 생각하는 추정치! 일것이다(…) ↩
-
원래값과 우리의 모델의 결과값인 예측값의 차이를 오차라고 한것이다. ↩
-
평균 0, 분산 1인 정규분포의 확률밀도에 관측치 \(\epsilon^{i}\) 를 넣은 식이다. ↩
-
우리가 만든 어떤 가설 H에 대한 우도(가능도)는 어떤 결과가 E가 있을때 H가 참일 경우 E가 나올 확률이다. H라는 원인하에 결과 E가 얻어질 확률..이라고 이해해보자.. ↩